
5.5 Questions with Eli Dart (ESnet), C.S. Chang, and Michael Churchill (PPPL)
In 2025, when the International Thermonuclear Experimental Reactor (ITER) generates “first plasma”, it will be the culmination of almost 40 years of effort. First started in 1985, the project has grown to include the scientific talents of seven members (China, EU, India, Japan, Korea, Russia, and the US, with EU membership bringing the total to 35 countries) and if successful, will mark the first time that a large scale fusion reactor generates more thermal power than is used to heat isotopes of hydrogen gas to a plasma state.
ESnet is supporting this international scientific community as this dream of limitless, clean energy is pursued. When operational at full capacity, ITER will generate approximately a petabyte-per-day of data, much of which will need to be analyzed and fed back in near real-time to optimize the fusion reaction and manage distribution of data to a federated framework of geographically distributed “remote control rooms” or RCR. To prepare for this demanding ability to distribute both data and analytics, recently ESnet’s Eli Dart and the Princeton Plasma Physics Laboratory’s (PPPL) Michael Churchill and C.S. Chang were co-authors on a test exercise performed with collaborators at Pacific Northwest National Laboratory (PNNL), PPPL, Oak Ridge National Laboratory (ORNL), and with the Korean KREONET, KSTAR, National Fusion Research Institute, and the Ulsan National Institute of Science and Technology. This study (https://doi.org/10.1080/15361055.2020.1851073) successfully demonstrated the use of ESnet and the ScienceDMZ architecture as part of trans-Pacific large data transfer, and near real-time movie creation and analysis of the KSTAR electron cyclotron emission images, via links between multiple paths at high sustained speeds.
Q 1: This was a complex test, involving several sites and analytic workflows. Can you walk our readers through the end-to-end workflow?
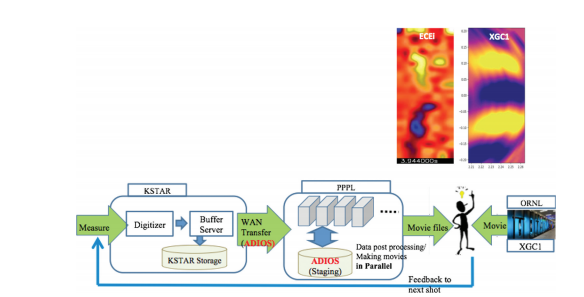
Eli Dart: The data were streamed from a system at KSTAR, encoded into ADIOS format, streamed to PPPL, rendered into movie frames, and visualized at PPPL. One of the key attributes of this workflow is that it is a streaming workflow. Specifically, this means that the data passes through the workflow steps (encoding in ADIOS format, transfer, rendering movie frames, showing the movie) without being written to non-volatile storage. This allows for performance improvements, because no time is spent on storage I/O. It also removes the restriction of storage allocations from the operation of the workflow – only the final data products need to be stored (if desired).
Q 2: A big portion of this research supports the idea of federated, near real-time analysis of data. In order to make these data transfers performant, flexible, and adaptable enough to meet the requirements for a future ITER RCR, you had to carefully engineer and coordinate with many parties. What was the hardest part of this experiment, and what lessons does it offer ITER?
Eli Dart: It is really important to ensure that the network path is clean. By “clean” I mean that the network needs to provide loss-free IP service for the experiment traffic. Because the fusion research community is globally distributed, the data transfers cover long distances, which greatly magnifies the negative impact of packet loss on transfer performance. Test and measurement (using perfSONAR) is very important to ensure that the network is clean, as is operational excellence to ensure that problems are fixed quickly if they arise. KREONET is an example of a well-run production network – their operational excellence contributed significantly to the success of this effort.
Q 3: One of the issues you had to work around was a firewall at one institution. What was involved in working with their site security, and how should those working with Science DMZ work through these issues?
Eli Dart: Building and operating a Science DMZ involves a combination of technical and organizational work. Different institutions have different policies, and the need for different levels of assurance depending on the nature of the work being done on the Science DMZ. The key is to understand that security policy is there for a reason, and to work with the parties involved in the context that makes sense from their perspective. Then, it’s just a matter of working together to find a workable solution that preserves safety from a cybersecurity perspective and also allows the science mission to succeed.
Q 4: How did you build this collaboration and how did you keep everyone on the same page, any advice you can offer other experiments facing the same need to coordinate multi-national efforts?
Eli Dart: From my perspective, this result demonstrates the value of multi-institution, multi-disciplinary collaborations for achieving important scientific outcomes. Modern science is complex, and we are increasingly in a place where only teams can bring all the necessary expertise to bear on a complex problem. The members of this team have worked together in smaller groups on a variety of projects over the years – those relationships were very valuable in achieving this result.
Q 5: In the paper you present a model for a federated remote framework workflow. Looking beyond ITER, are there other applications you can see for the lessons learned from this experiment?
C.S. Chang: Lessons learned from this experiment can be applied to many other distributed scientific, industrial, and commercial applications which require collaborative data analysis and decision making. We do not need to look too far. Expensive scientific studies on exascale computers will most likely be collaborative efforts among geographically distributed scientists who want to analyze the simulation data and share/combine the findings in near-real-time for speedy scientific discovery and for steering of ongoing or next simulations. The lessons learned here can influence the remote collaboration workflow used in high energy physics, climate science, space physics, and others.
Q 5.5: What’s next? You mention quite a number of possible follow on activities in the paper? Which of these most interest you, and what might follow?
Michael Churchill: Continued work by this group has led to the recently developed open-source Python framework, DELTA, for streaming data from experiments to remote compute centers, using ADIOS for streaming over wide-area networks, and on the receiver side using asynchronous Message Passing Interface to do parallel processing of the data streams. We’ve used this for streaming data from KSTAR to the NERSC Cori supercomputer and completing a spectral analysis in parallel in less than 10 minutes, which normally in serial would take 12 hours. Frameworks such as this, enabling connecting experiments to remote high-performance computers, will open up the quality and quantity of analysis workflows that experimental scientists can run. It’s exciting to see how this can help accelerate the progress of science around the world.
Congratulations on your success! This is a significant step forward in building the data management capability that ITER will need.