EJFAT prototype demonstrates proof of concept for connecting scientific instruments with remote high-performance computing for rapid data processing
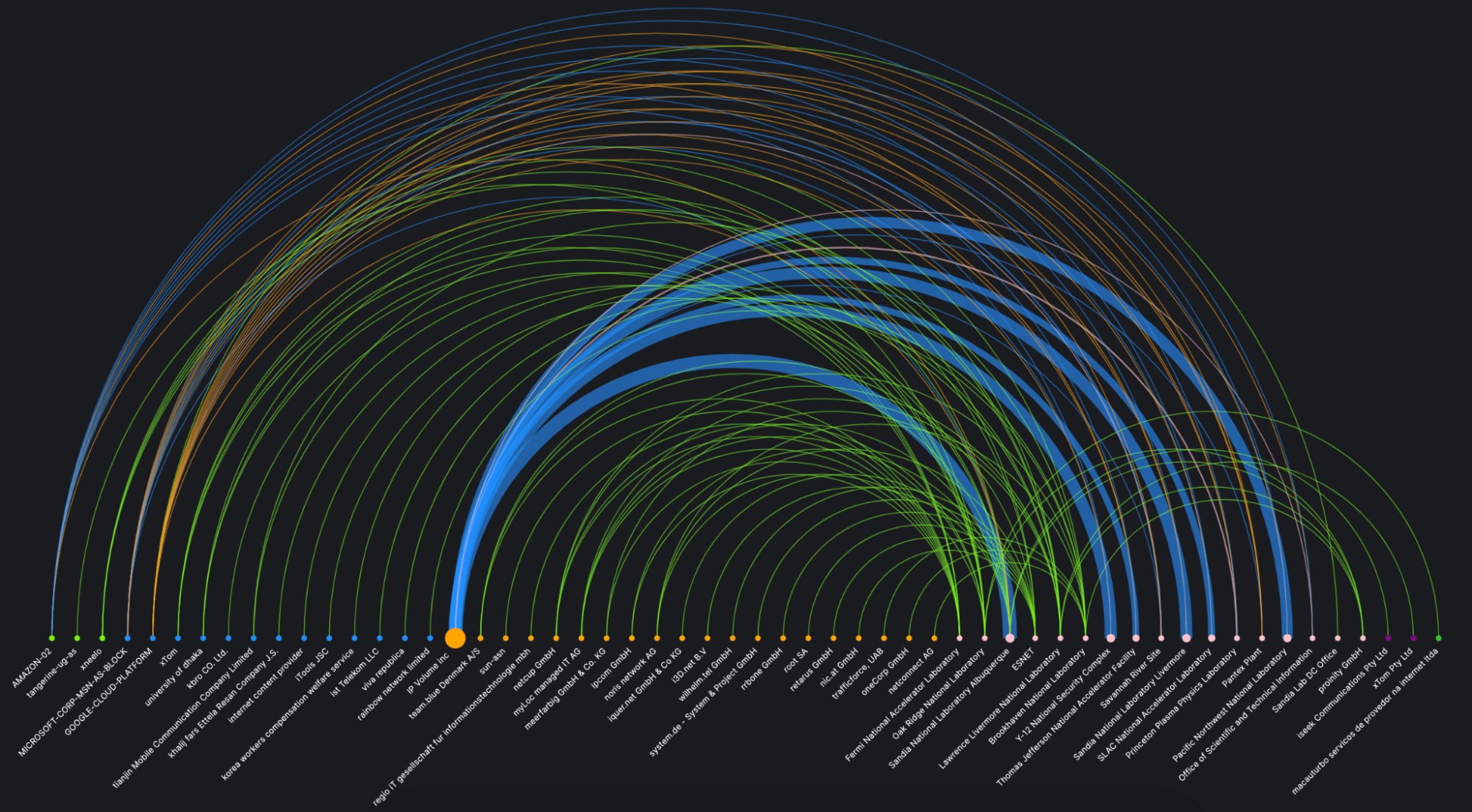
Scientists at Thomas Jefferson National Accelerator Facility (Jefferson Lab) clicked a button and held their collective breaths. Moments later, they exulted as a monitor showed steady saturation of their new 100 gigabit-per-second connection with raw data from a nuclear physics experiment. Across the country, their collaborators at Energy Sciences Network (ESnet) were also cheering: the data torrent was streaming flawlessly in real time from 3,000 miles away, across the ESnet6 network backbone, and into the National Energy Research Scientific Computing Center’s (NERSC‘s) Perlmutter supercomputer at Lawrence Berkeley National Laboratory (Berkeley Lab).
Once it reached NERSC, 40 Perlmutter nodes (more than 10,000 cores) massively processed the data stream and sent the results back to Jefferson Lab in real time for validation, persistence, and final physics analysis. This was achieved without the need for any buffering or temporal storage and without experiencing data loss or latency-related problems. (In this context, “real time” means streamed continuously while processing is performed, with no significant delays or storage bottlenecks.)
This was only a test — but not just any test. “This was a major breakthrough for the transmission and processing of scientific data,” said Graham Heyes, Technical Director of the High Performance Data Facility (HPDF). “Capturing this data and processing it in real time is challenging enough; doing it when the data source and destination are separated by distances on continental scales is very difficult. This proof-of-concept test shows that it can be done and will be a game changer.”
Twenty-five years ago Saturday, on August 3, 1999, IPv6 history was made: ESnet was issued its IPv6 production netblock, which is still in use today. The American Registry for Internet Numbers (ARIN) assigned the very first block out of its 2001:400::/23 allocation, and since then, ESnet has numbered its production IPv6 services out of 2001:400::/32. (The netblock would have originally been a /35, later increased to /32 automatically by the RIRs.)
This was the first production IPv6 address allocation in North America, and possibly the world. Akira Kato, a global Internet pioneer, member of the WIDE Project, and a professor at Keio University, notes that the WIDE project did receive the first allocation in the Asia-Pacific region 8 days after the allocation of ESnet’s space. WIDE, along with its sub-project, KAME, would go on to develop critical IPv6 software, some of which is still in use today. (WIDE continues to have the numerically-lowest globally routable production IPv6 address, 2001:200::/32.)
IPv6 is the current generation Internet Protocol, and it has been in an extended process of supplanting the now-legacy IPv4. Developed in the early 1990s, it was adopted by ESnet as part of a larger effort to lead by example–by embracing cutting-edge protocols and technologies. IPv6’s massive address space was originally seen as a way of effectively “saving the Internet” from potential collapse due to the exhaustion of IPv4’s more limited address space. While mechanisms such as network address translation (NAT) were developed to extend IPv4’s life, ESnet quickly recognized the drawbacks that these mechanisms created, especially in the high-performance computing and networking environments ESnet supported. Hence, the move to IPv6 was an obvious one for ESnet, and the organization encouraged other National Labs to follow suit.
Before Production
ESnet’s involvement in IPv6 predates our effective move to production by at least three years. As we noted in 2021:
Bob Fink, Tony Hain, and Becca Nitzan [all ESnet staff at the time, circa 1996] spearheaded early IPv6 adoption processes, and their efforts reached far beyond ESnet and the Department of Energy (DOE). The trio were instrumental in establishing a set of operational practices and testbeds under the auspices of the Internet Engineering Task Force–the body where IPv6 was standardized–and this led to the development of a worldwide collaboration known as the 6bone. 6bone was a set of tunnels that allowed IPv6 “islands” to be connected, forming a global overlay network. More importantly, it was a collaboration that brought together commercial and research networks, vendors, and scientists, all with the goal of creating a robust internet protocol for the future.
In addition to 6bone, ESnet was one of three principals that created and managed 6tap, one of the first IPv6 internet exchanges. Collocated at the Starlight research and education network exchange in Chicago, 6tap represented a collaboration between ESnet and Canadian partners CANARIE and Viagenie.
Moving to Native IPv6
With experience gained in the 6bone and 6tap projects, ESnet staff, with other partners in the Internet, began to advance the cause of the creation of a production IPv6 network. The goal would ultimately be a native IPv6 network–no overlays, no tunnels. This would require new blocks of address space to be delegated to the still-nascent Regional Internet Registries (at the time, ARIN in the Americas, APNIC in Asia-Pacific, and RIPE-NCC in Europe and the Middle East/Africa). Those RIRs would need policies and procedures for allocating IPv6 address space. But first, they needed to get their own blocks from the Internet Assigned Numbers Authority (IANA). After nearly two years of deliberation (and much input from ESnet staff to bodies like the IETF and RIRs), IANA made the assignments on July 14, 1999:
After much discussion concerning the policy guidelines for the deployment of IPv6 addresses, in addition to the years of technical development done throughout the Internet community, the IANA has delegated the initial IPv6 address space to the regional registries in order to begin immediate worldwide deployment of IPv6 addresses.
We would like to thank the current Regional Internet Registries (RIR) for their invaluable work in the construction of the policy guidelines, which seem to have general consensus from the Internet community. We would also like to thank the efforts of the IETF community and the support of the IAB in making this effort a reality.
The stage was now set for ESnet to receive the first public production IPv6 addresses, and help usher in a new era for the Internet. Thus, while Tony Hain and Bob Fink were busy chairing IETF working groups and writing RFCs, Becca Nitzan began building a production IPv6 network within ESnet. Nitzan configured her DEC Alpha workstation, hershey.es.net, to be dual stack–possibly the first workstation in North America, if not the world, to be on a production IPv6 network.
hershey.es.net, a DEC Alpha Personal Workstation, is reputed to be the first computer on the production IPv6 network. It still runs (OpenBSD now instead of Digital Unix) and also serves as a valuable foot-rest and space-heater for the author.
ESnet continues to maintain hershey’s historic EUI64-based IPv6 AAAA entry in the public es.net domain.
2008 – Present: New Generation(s) Take Over
Eventually, Hain, Fink, and Nitzan all moved on from ESnet, either into the private sector or retirement, but a new generation took over to continue IPv6 development in the Department of Energy’s research network:
Kevin Oberman carried the torch of IPv6 evangelist in ESnet, promoting the protocol and educating DoE sites about the virtues of the new technology.
Michael O’Connor developed the first tools for network monitoring and topology discovery in ESnet–and made them exclusively run over IPv6.
When it came time for Oberman to retire, Michael Sinatra transferred from UC Berkeley to ESnet to become IPv6 and DNS subject matter expert. He proceeded to unite IPv6 and IPv4 routing under a single interior routing protocol, developed tools to manage the IPv6 side of ESnet’s rich peering infrastructure, continued educating research and education and government networks on the risks of not adopting IPv6, and is currently involved in building a segment-routed network capable of carrying both IPv4 and IPv6 traffic while only using IPv6–eliminating IPv4–for the control plane.
Nick Buraglio joined ESnet in 2013 and has continued in the tradition of Hain and Fink, spearheading DoE and other US Government agency adoption of IPv6–and, more importantly, abatement of IPv4 within those agencies. He is now a co-chair of the IPv6 Operations (v6ops) Internet Engineering Task Force (IETF) working group, and continues to advance and evangelize for the protocol.
Buraglio, Paul Wefel, Dylan Jacob, and John J. Christman worked to design and construct an IPv6-only management plane for the ESnet6 network, requiring substantial cooperation from vendors, some of whom had not previously had any requirements for IPv6-only management capabilities. It has allowed ESnet to inch closer to achieving the US Government’s IPv4 abatement mandates.
Dale Carder joined ESnet in 2016 and has recently worked on an innovative use of the IPv6 packet header flow label field as a mechanism to mark IPv6 traffic based on the scientific project that is generating and receiving the traffic. This is providing valuable information on how, for example, the various Large Hadron Collider research projects are using the network and the relative network capacity demands they are producing.
Going into the second quarter-century of production IPv6 in ESnet, IPv6 is no longer a core component of ESnet’s services. It is the core component. Nick and I continue to work together in our respective roles, along with other ESnet engineers, to advance the protocol, both from a strategic perspective and in the day-to-day operations of our organization.
As we move into another new era–one characterized by the movement away from dual-stack to an IPv6-only world, expect Nick, myself, and others to continue our work in bringing the Internet beyond IPv4. In the next few weeks, I plan to revisit my “Risks of not deploying IPv6” in an effort to determine what risks have been realized and what have been mitigated over the past dozen years. We will also be doing an overview of the most recent LHC Data Challenge, with a focus on IPv6’s nearly exclusive role as the data-transfer substrate for this major high-energy physics project. Nick will continue to advance IPv6 operations via his role in the IETF. Members of ESnet’s Data-centers and Facilities Team are inching closer to IPv6-only data centers and zero-touch provisioning (ZTP). My hope is that we will make as much progress in the next five years as we have in the previous twenty-five. Regardless, ESnet’s role in the history of IPv6 has prepared us well to lead us into a bright, IPv6-only future.
A recent post on Microsoft’s Networking blog, clickably titled “Three Reasons Why You Should Not Use iPerf3 on Windows,” caused a mini-kerfuffle in the world of network speed measurement and a lively discussion in the comments section. Although the post has since been updated with some important disclaimers — the no. 1 answer to the question being that ESnet has never and still does not support Windows for iperf3 — ESnet’s iperf3 team wanted to set the record straight on a few additional points publicly for anyone who might still be confused.
A little background on ESnet and iperf3 ESnet (www.es.net) provides scientific networking services to support the U.S. Department of Energy and its national laboratories, user facilities, and scientific instruments complex. We developed iperf3 as a rewrite of iperf2 in order to be able to test the end-to-end performance of networks doing large transfers of scientific data. The primary consumer of iperf3 is the perfSONAR measurement system), which is widely used in the research and education (R&E) networking community. iperf3 is of course also usable as a standalone tool, which is one of the reasons it’s been released separately on GitHub. Many large corporations, including SpaceX’s Starlink and Comcast, are using it to measure their own networks. It has been downloaded from GitHub nearly 100,000 times according to a third-party tool; this does not measure the other ways that users could acquire iperf3.
Work on iperf3 started in 2009 (the first commit was an import of the iperf-2.0 sources), with the first public release in 2013. The commit history (and the original iperf2 project maintainer) will confirm that iperf3 was intended essentially as an iperf2 replacement. Thus there was a time during which iperf2 was basically abandonware. Fortunately, Bob McMahon from Broadcom has assumed the maintainership of this code base and is actively developing for it.
Linux vs. other operating systems
Most of the high-performance networking that we see in the R&E networking space comes from Linux hosts, so it was natural that this is the main supported platform. Supporting iperf3 on FreeBSD and macOS has ensured some level of cross-platform support, at least to the extent of other UNIX and UNIX-like systems. While we have had many requests to make iperf3 work under Windows, we didn’t have the developer skills or resources to support that — and we still don’t. The fact that iperf3 works on Windows at all is a result of code contributions from the community, which we gratefully acknowledge.
There are many facets to end-to-end application network performance. These include of course routers, switches, NICs, and network links, but also the end host operating system, runtime libraries, and the application itself. To that extent iperf3 does characterize the performance of a certain set of applications designed for UNIX but trying to run (with some emulation or adaptation) in a Windows environment. We completely agree that this may not provide the highest throughput numbers on Windows, compared to a program that uses native APIs.
Iperf3 and Windows
ESnet is happy to see that iperf.fr has removed the old, obsolete binaries from their Web site. This is a problem that can affect any open-source project, not just iperf3.
As mentioned earlier, we’ve generally accepted patches for iperf3 to run on Windows (or other not-officially-supported operating systems such as Android, iOS, or various commercial UNIXes). These changes have allowed Windows hosts to run iperf3 tests (apparently with sub-optimal performance) against any other instance of iperf3, regardless of operating system.
If there’s interest on the part of Microsoft in making a more-Windows-friendly version of iperf3, we’d welcome a conversation on that topic. Feel free to reach out to me (Bruce Mah) anytime.
Among this summer’s cohort of 53 Experiences in Research high school interns are three from Hawai’i and two from the Bay Area who are working on similar but different network data visualization projects for ESnet.
“Much of the things I am doing in the project were things I could not have imagined were in my ability to try a month ago,” said Ella Jeon, a rising junior in Pleasanton, CA. “One significant new mindset I have experienced over the course of this internship is the whole ‘being able to try things that I didn’t think were really possible or something I was really capable of’ type of realization. The boost of guidance and support in this internship has made me realize how much more I could go on to try and achieve on my own as well.”
Diagram of ESnet6’s peering points for the new Cloud Connect Service
By Joshua Stewart, ESnet
Part of managing a network dedicated to handling vast swaths of scientific data is also ensuring it adapts to trends for how data is being created, stored, and computed. A pattern has emerged in recent years allowing for access to elastic and scalable systems on demand. Nebulously titled “The Cloud,” it refers to software and services that run over the public internet. For ESnet, this is just another place where science intends to happen.
To drill down more on the nebulosity of the term “The Cloud,” there are different flavors of how the services/software are consumed. “Public Cloud” refers to services and software that are open for all users and subscribers around the world: for example, those provided by Dropbox, Slack, Salesforce, and Office 365. Meanwhile, as its name suggests, a Virtual Private Cloud (VPC) is an environment in which all virtualized hardware and software resources are dedicated exclusively to, and accessible only by, a single organization. The intention of a VPC is to emulate the on-premise data centers of old while removing the headaches of managing their physicality (space and power constraints), and offering the added benefit of instantaneous access to scale when needed. Although some organizations decided to go all-in on the new virtual environments by harnessing a cloud-native posture, some took a more measured approach by seamlessly blending their on-premises infrastructure with the new virtualized territory, in a format also known as a hybrid cloud.
As usage of virtual private clouds grew, it became apparent that connectivity over the public internet was too unreliable, slow, and insecure: dedicated, high-bandwidth connectivity was a must-have. In response, every major Cloud Service Provider (CSP) launched an offering. Amazon Web Services (AWS) was first, launching “Direct Connect” in 2012; Azure followed in 2014 with its “ExpressRoute”; and in 2017, Google launched Cloud Interconnect. (Read more about the history.)
These virtual circuits are the driver behind the new ESnet Cloud Connect service aimed at supporting both scientific and enterprise workloads. The goal is to carve out a dedicated, high-bandwidth path (up to 10 Gbps) across ESnet’s 400GE-capable backbone from any supported user facility to the nearest cloud on-ramp by utilizing two interim network service providers: Packet Fabric and Equinix. From there, ESnet would help provision the major CSPs’ (Azure, AWS, GCP) aforementioned flavor of dedicated connectivity into your Virtual Private Cloud.
This solution is designed to scale from simple dedicated connectivity and a singular cloud provider to a virtual routed network utilizing multiple cloud providers, onramps, and interconnecting user facilities. This series of blog posts will focus on a few suggested use cases for utilizing ESnet’s new service offering. For questions or to learn more, email Joshua Stewart.
ESnet Measurement & Analysis Intern Felix Renken is a senior student from Technische Universität Berlin, majoring in Computer Science with a focus on Media Technologies and Signal Processing. Originally from a rural area near Hamburg in northern Germany, he moved to Berlin to pursue his college education. He arrived in Berkeley in March and will be going home in early July.
During his internship, Felix worked on developing an open-source Grafana plugin for visualizing network data that can be used in ESnet’s Stardust system, which collects precise network measurement data and allows users to retrieve information about specific equipment over a given time range. (Learn more about Stardust via this talk by Ed Balas and Andy Lake.) Felix’s plugin enables users to visualize various data collected by Stardust, revealing the relationship between pairs of data from different destinations for a single source and showcasing common attributes in nodes and links along with the option to visualize AS paths. The plugin is currently undergoing the Grafana community plugin review process; the source code is available on GitHub. It is installed on Stardust too, for anyone who wants to check it out.
During my search for interesting internship opportunities, I came across ESnet’s student program and contacted Marc Körner and Katrina Turner to get more information on the projects they supervise. I eventually applied for the “Data Visualization of Network Measurement Data” project. It encompasses the development of an open-source tool that visualizes network data in an exciting way. The opportunity of getting work experience in a research environment greatly appealed to me. And, of course, the chance to spend time in California!
What is the most exciting aspect of your field right now?
The cross-disciplinary nature of visualizing data is particularly interesting to me. It utilizes principles from design, statistics, and computer science, offering opportunities to learn from diverse perspectives.
How was Berkeley different from Berlin? What fun things did you do here?
Berkeley and Berlin are distinct in so many aspects. Berkeley is, of course, much smaller in size than Berlin, and I really enjoyed being in a city that is less hectic. People here seem more relaxed. And the fact that Berkeley is somewhat shaped by its university was also something that I’m not used to from Berlin or any other German city. Cycling here was scarier than in Berlin though. Another thing is the accessibility to the fantastic nature around Berkeley. I went hiking a lot and will definitely miss being in close proximity to beautiful trails when going back to Germany. Other fun things I did were camping and eating a lot of burritos.
Network cybersecurity must strike a delicate balance between openness and safety. ESnet has long focused more on the first, in order to facilitate scientific communication, data sharing, and collaboration. But in today’s Wild West of ransomware, phishing, and other threats, safeguarding this vital network is equally critical.
Deputy Chief Information Security Officer (CISO) Alex Withers oversees a reorganized, two-part structure for security at ESnet: the Security Engineering group, which he heads, and a new Threat & Vulnerability Management group, which Chief Security Officer Adam Slagell is leading during the search for a senior threat hunter/DOE community coordinator. For Security Engineering, among Alex’s responsibilities are overseeing ESnet’s effort to comply with the federal Zero Trust requirements — an approach to cybersecurity that goes beyond “trust but verify” and treats all networks and traffic as potential threats. Alex will be making sure that any new security policies, procedures, and architecture do not impede ESnet’s vision of enabling scientific progress that is completely unconstrained by the physical location of instruments, people, computational resources, or data.
Alex has deep experience in threat intelligence sharing, policy and compliance, and security architecture. Most recently he was the CISO and cybersecurity division manager at the National Center for Supercomputing Applications at the University of Illinois. While at NCSA, Alex oversaw groups responsible for security operations, applied cybersecurity research, cybersecurity engagement, and scientific computing in the HIPAA and Controlled Unclassified Information [CUI] space. He was a PI or co-PI on several National Science Foundation awards for projects focused on intrusion detection, threat intelligence dissemination, and capabilities-based authorization for access to scientific computing resources. Before NCSA, Alex worked for Brookhaven National Laboratory as a security and systems engineer for over 10 years.
Alex grew up in Alaska and now lives in Urbana, Illinois, where he works out of ESnet’s Champaign office with Adam and Security Engineering team members Kapil Agrawal, Michael Dophelde, and Sam Oehlert, as well as about a dozen other ESnetters. He’s an avid long-distance runner – as are his wife and two of his four children. In the last few years, Alex has completed around a dozen ultra-marathons, or “ultras,” ranging from 50 km to 100 miles – something he’s “always reluctant to tell people about because it sounds crazy.”
What brought you to ESnet?
Really it was the opportunity for growth — both to tackle new challenges in cybersecurity architecture and for me professionally, to try something new. ESnet is responsible for connecting a massive portion of the scientific computing infrastructure that supports not just this country’s scientific investments but also international collaborations. It’s growing extremely rapidly, and it’s a giant target for all sorts of reasons, whether from state-sponsored attacks or cyber criminals or anything in between. And so it looks like an immense challenge, and that’s very attractive to me.
What is the most exciting thing going on in your field right now?
There’s been a shift in how people view cybersecurity that’s making it easier for us to collaborate and innovate with users.
Traditionally, cybersecurity has had a bad reputation as being the people who say “No, you can’t do this; no, you can’t do that.” And in the research and education sector, the culture tends to be much more open, much more about getting done what has to be done, whether that’s moving data around or access to computing for scientists and their students. That culture has often bumped up against cybersecurity, which tends to want to wall things off. But cybersecurity is now much more about enabling science. As I tell people, “Listen, the funding agencies, the government, have invested billions of dollars in science and in this infrastructure that you rely on for your particle accelerator, electron microscope, whatever. And we want to protect that investment, because at the end of the day, things like cybersecurity incidents, they can disrupt your work. They can stop it dead in its tracks, and that’s money that’s lost.”
So today’s cybersecurity is about understanding how researchers use these systems and devices, how they access them through the network – and working together to make sure that we enable their use and make it available while at the same time very secure. At ESnet, we want to ensure the integrity of the data so that researchers can be productive on their computational systems and networks. That frame of approach is easier than traditional cybersecurity, which is more focused on things like confidentiality and privacy.
What book, movie, or podcast would you recommend?
A podcast I’ve been really enjoying has been “Some Work, All Play” by David Roche and Megan Roche. It’s an excellent inclusive running podcast for all runners, especially trail running, which is a hobby I enjoy.
Running ultras sounds like a little more than just a “hobby.” Tell us more about why you do it?
Well, a lot of people think of it as a very physical sort of endeavor. And I mean…that’s true, and I don’t want to downplay that, but you’d be surprised to find out that it’s not as difficult as you think it is. The real challenge is the mental challenge. It is extremely difficult mentally to go out on a trail and run for hours and hours and hours and hours. You’re really fighting against the urge to drop out and call it a day. And sometimes you’re not successful.
What’s great about it is pushing yourself up against the limits of what you can do. There are people who seriously race these things, and they win. I’m not in any danger of doing that, I assure you. For me, it’s racing against various aspects of yourself. Racing against yourself mentally. Racing against your past self. Maybe you’re going to do better on a race you’ve done before. Sometimes you’re racing against your own stomach, because you have to eat during these things—but it’s not a pleasant task to eat while you’re doing all this running!
It’s very challenging, but it’s also a lot of fun. It’s very rewarding when it works out.
ESnet software engineers Sarah Larsen, Dan Doyle, and Bruce Mah at ESnet’s High Touch demonstration booth
After a pandemic-related in-person hiatus, the Optical Fiber Communication Conference and Exhibition (OFC), sponsored by Optica, IEEE Communication Society, and IEEE Photonics Society, resumed operations with a sold-out event in March 2023 at the San Diego Convention center. More than 11,500 participants and 515 exhibitors attended this global event for optical communications and networking, including almost two dozen from ESnet. Planning & Architecture Acting Group Lead Chris Tracy led ESnet’s multifaceted involvement at OFC23, which ranged from a booth demonstrating ESnet’s High Touch project and panel discussion to helping implement OFCnet, an unconventional high-speed network connecting the show floor to a research center in Chicago.
Staffed by ESnet software engineers Bruce Mah, Sarah Larsen, and Dan Doyle, the ESnet booth presented a high-level technical overview and showed examples of data and analysis from the High-Touch system being deployed in ESnet6, the latest version of ESnet’s backbone network for supporting scientific collaborations and research around the globe. The High-Touch project uses a combination of software and programmable, off-the-shelf hardware to deliver new network services. Its first applications provide high-precision network telemetry, including summarization of network flows and capture of packet headers, which are computed from unsampled streams of packets from multiple 100GE and 400GE links. This demonstration relied heavily on the efforts of ESnet’s Infrastructure team to install and configure dozens of data collection servers across ESnet’s network footprint.
ESnet High-Touch Architecture and Design: This diagram shows the flow of packets and network measurements through ESnet’s High-Touch system, which uses a combination of programmable, off-the-shelf hardware and software to provide high-precision network telemetry.
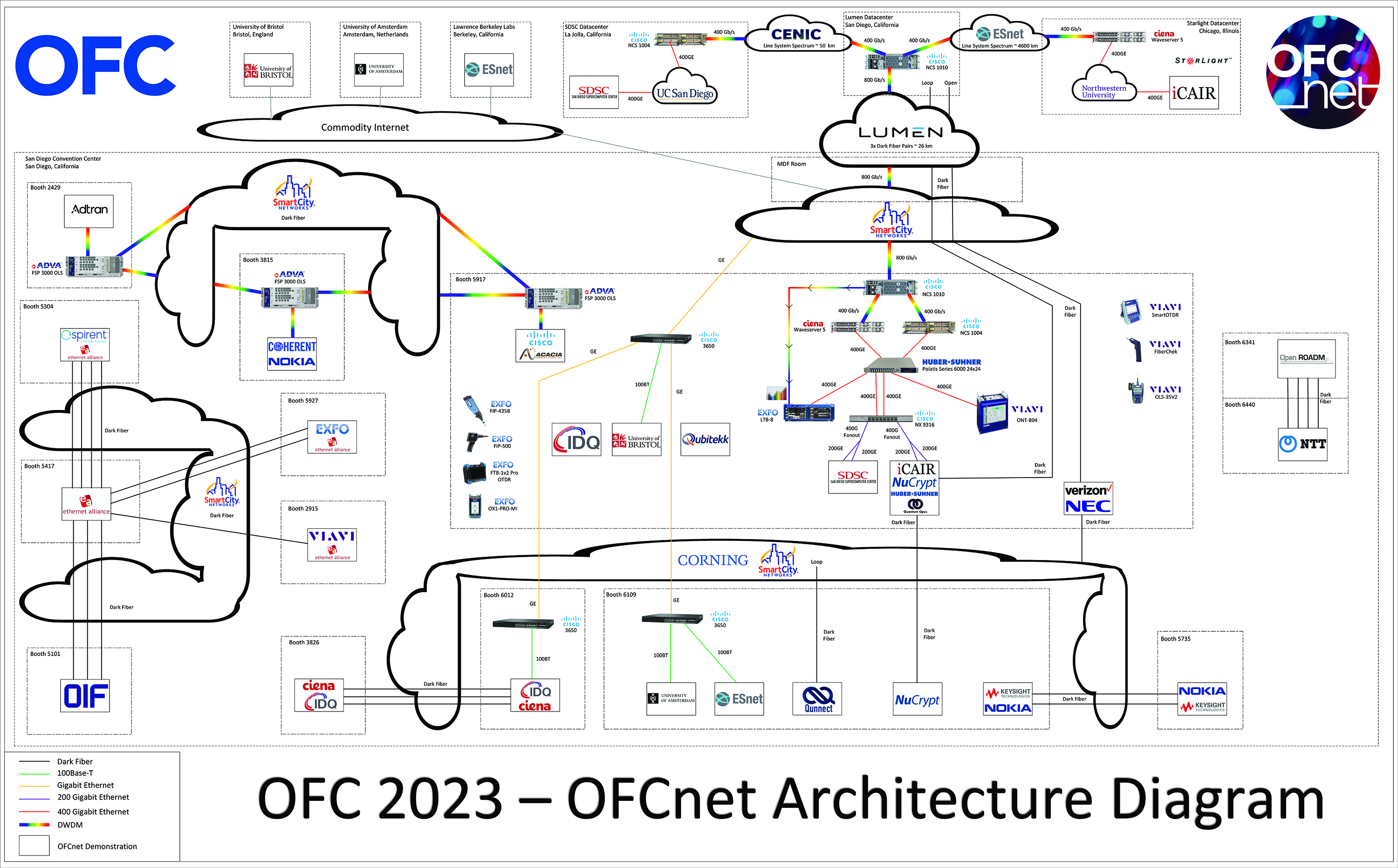
ESnet Executive Director Inder Monga and Chris also realized that OFC2023 offered potential for demonstrating network capabilities that went beyond the exhibition floor. Prior to OFC2022, there was no high-speed, “external” network connectivity at the event suitable for data-intensive demonstrations. The conference consisted of technical talks about papers that were being published and vendor booths. At OFC2022, Optica, Lumen, CENIC, Ciena and Smart City successfully showed in a modest proof of concept that external fiber could be brought into the convention center so that a live demonstration could be run on the show floor. For OFC2023, Ciena’s office of the CTO – who was leading the OFCnet effort – approached ESnet about demonstrating high-performance networking applications as well as emerging technologies, and more broadly, bringing some networking focus into the conference.
Working with Ciena staff, ESnet Network Services Optical Network Group Lead Patrick Dorn and Network Engineers Michael Blodgett, Kate Robinson, and Nathan Miller helped build an un-regenerated 400 Gbps link between the OFC show floor in San Diego and the StarLight Data Center in Chicago. “Un-regenerated” means the signal remains solely in the optical domain, e.g. as wavelengths of light, not an electrical signal, for transcontinental distances (more than 4,600 kilometers).
Another interesting feature of this demonstration was that the ESnet team connected ESnet6’s production Infinera FlexILS line system to a Cisco NCS 1010 line system (provided by Cisco to support OFCnet), effectively bridging the purpose-built OFC exhibition network to a live, nation-scale infrastructure. In addition to the Infinera and Cisco line systems, Ciena provided the ultra-long-haul transponder equipment necessary to communicate over such distances, plus the engineering expertise – along with staff from Cisco, ESnet and CENIC – to ensure it all worked.
Using the high-speed channel ESnet established between San Diego and Chicago, researchers from Northwestern University’s International Center for Advanced Internet Research (iCAIR) could showcase data transfer applications being used to move massive scientific datasets. By helping to implement this somewhat unconventional infrastructure, the ESnet team sought to show what might someday be possible when networks can transport 400 Gigabit Ethernet over such long distances without relying on bonding two 200 Gbps wavelengths using inverse muxing.
Some of the ESnet team at OFC23
In addition to the two demonstrations, ESnet staff participated in multiple panel discussions and a bird of a feather (BoF) event at OFC23. For a panel on how high performance research networks continue to drive fundamental science and innovation, Chris Tracy and others used OFCnet and its connection to an external Research & Education network to discuss data transfer for data intensive science, detailed monitoring of science flows within the network, network security considerations in the research network environment, and applications like distributed computing that take advantage of these networks. At the BoF event, Inder presented, while Chris, ESnet staff, and other OFCnet volunteers brainstormed ideas for how OFCnet might evolve as a next-generation optical photonic network for OFC2024. One recommendation: a Sunday workshop titled: “How Can OFC with a Real-Life Testbed Accelerate Innovation in the Design and Operation of Next Generation Optical Photonic Networks?” The BoF participants believe this would provide an opportunity to invite speakers and publish papers within the context of the workshop for these kinds of networking-related topics.
Planning for next year’s iteration of OFCnet (March 24-28, 2024) has already kicked off, with ESnet once again participating in a leadership role. The goals for OFCnet24 are ambitious. The volunteer team hopes to attract attendees from different communities, such as networking science (academia and research labs); make it possible to showcase high performance networking application use cases and other emerging technologies – turning the exhibits floor as a science accelerator; and bridge the exhibit and technical programs by offering the opportunity to present advanced technical papers with live demos.
“It was great to be able to demonstrate some of the innovative services we’re delivering through the High Touch project,” said Chris. “And of course we welcome any opportunity for ESnet to participate in something such as OFCnet that advances the state of the art for networking and allows us to showcase emerging technologies on our network. Next year is going to be even more exciting.”
Marc Lyonnais (right), OFCnet chair and director of external research at Ciena, presented Planning & Architecture Acting Group Lead Chris Tracy (left) and Executive Director Inder Monga (center) with a plaque in thanks for ESnet’s OFCnet efforts
ESnet’s second annual Confab gathering is designed for scientists across all disciplines who want to vastly improve their workflows and collaborations to accelerate time to discovery; for network engineers from national labs and universities who support science IT services for researchers on their campuses; and for the research networking professionals who partner with ESnet to move data across the world.
Last year’s inaugural Confab in Berkeley, held concurrently with the unveiling of ESnet6, was a fun and resounding success — and we believe Confab23 will continue and broaden the conversation we started.
Confab23 will showcase scientists who use ESnet today to perform real-time data analysis, leverage multiple supercomputers in parallel for large-scale simulations, and collaborate with colleagues on experiments as if side by side while thousands of miles apart – among many other applications.
Together we can chart the future of scientific data management and integrated scientific infrastructure.
In addition to lively conversation and informal technical discussions between our ESnet, DOE, and scientific community attendees, the program includes:
Updates and discussions with the Department of Energy on major initiatives, such as the Integrated Research Infrastructure initiative and the High Performance Data Facility, that support our shared vision — that scientific progress will be completely unconstrained by the physical location of instruments, people, computational resources, or data.
Scientific keynotes by Nicholas Schwarz on Light Source and BES developments, and Amadeo Perazzo, on LCLS and DOE HPC collaboration
An overview of quantum networking activities by Inder Monga, part of a lively evening program
We will also hold a meeting of the ESnet Site Coordinator Committee at the same venue on October 19 and 20.
If you have any questions or suggestions – or would like to offer a presentation or session topic – please email our workshop team directly at confab@es.net.
DOE Office of Project Assessment Director Kurt W. Fisher and ESnet Network Services Group Lead Kate Petersen Mace, ESnet6 project director, who accepted the award on behalf of the ESnet6 team
It’s rare for any technology project to be completed early and under budget — let alone a massively complex one involving extensive hardware and software upgrades across many states. Yet Energy Sciences Network’s (ESnet) ESnet6 project was finished more than two years ahead of schedule and for less than it was estimated. In recognition of this unusual feat, the Department of Energy (DOE) recently presented ESnet with a special Project Assessment Award. (As an IT project, ESnet6 is not eligible for the DOE’s Project Management Awards.)
ESnet6 is the newest iteration of the DOE’s high-performance network, also known as the “data circulatory system” for the DOE science complex. Not only did ESnet6 boost bandwidth to more than 46 Terabits per second — a significant increase – it also automated network operations for scalability and reliability, improved security services, and replaced aging equipment. In addition, ESnet6 offers greater programmable network flexibility that will support evolving computation and data models in the emerging exabyte data era.
Six years in the making, ESnet6 was completed well under budget six months before the forecasted early finish date of January 2023 – and more than two years ahead of the forecasted CD-4 date in January 2025.
DOE Office of Project Assessment Director Kurt W. Fisher presented the award in a private ceremony at the DOE Project Management Workshop in Washington, DC, in April. ESnet Network Services Group Lead Kate Petersen Mace, ESnet6’s project director, accepted on behalf of the ESnet6 team.
“ESnet6 represents the culmination of several years of extraordinary commitment and tireless dedication by all of ESnet’s staff,” said Inder Monga, ESnet’s executive director. “We’re grateful to Berkeley Lab for its support and to DOE for recognizing the collective efforts of the team behind this critical piece of scientific infrastructure.”
Part of the ESnet6 team smiling at the CD-4 Review meeting, joined by reviewers and DOE representatives.
















{kind=link}
You must be logged in to post a comment.