

The Advanced North Atlantic (ANA) collaboration has added three 400-Gbps spectrum circuits between exchange points in the U.S., U.K., and France, boosting ANA’s combined trans-Atlantic network capacity to 2.4 Tbps. READ MORE
The Advanced North Atlantic (ANA) collaboration has added three 400-Gbps spectrum circuits between exchange points in the U.S., U.K., and France, boosting ANA’s combined trans-Atlantic network capacity to 2.4 Tbps. READ MORE

Leading research and education (R&E) networking organizations Energy Sciences Network (ESnet), GÉANT, GlobalNOC at Indiana University, Internet2, and Texas Advanced Computing Center (TACC) have joined forces to form MetrANOVA, a consortium for Advancing Network Observation, Visualization, and Analysis. MetrANOVA’s goal is to develop and disseminate common network measurement and analysis tools, tactics, and techniques that can be applied throughout the global R&E community. READ MORE
ESnet has released iperf-3.16, a significant new version of the open-source network performance measurement tool iperf3. Part of perfSONAR, iperf3 can also be used as a stand-alone tool for measuring network performance in general. The new version gives better insights into high-speed network behaviors. READ MORE
A combined team from ESnet and Lehigh University was awarded the best paper for Exploring the BBRv2 Congestion Control Algorithm for use on Data Transfer Nodes at the 8th IEEE/ACM International Workshop on Innovating the Network for Data-Intensive Science (INDIS 2021), which was held in conjunction with the 2021 IEEE/ACM International Conference for High Performance Computing, Networking, Storage and Analysis (SC21) on Monday, November 15, 2021.
The team was comprised of:
The paper can be found here. Slides from the presentation are here. In this Q+A, ESnet spoke with the award-winning team about their research — answers are from the team as a whole.

The paper is based on extensive testing and controlled experiments with the BBR (Bottleneck Bandwidth and Round-trip propagation time), BBRv2 and the Cubic Function Binary Increase Congestion Control (CUBIC) Transmission Control Protocol (TCP) Internet congestion algorithms. What was the biggest lesson from this testing?
BBRv2 represents a fundamentally different approach to TCP congestion control. CUBIC (as well as Hamilton, Reno, and many others) are loss-based, meaning that they interpret packet loss as congestion and therefore require significant network engineering effort to achieve high performance. BBRv2 is different in that it measures the network path and builds a model of the path – it then paces itself to avoid loss and queueing. In practical terms, this means that BBRv2 is resilient to packet loss in a way that CUBIC is not. This comes through loud and clear in our data.
What part of the testing was the most difficult and/or interesting?
We ran a large number of tests in a wide range of scenarios. It can be difficult to keep track of all the test configurations, so we wrote a “test harness” in python that allowed us to keep track of all the testing parameters and resulting data sets.
The harness also allowed us to better compare results collected over real-world paths to those in our testbed environments. Managing the deployment of the testing environment though containers also allowed for rapid setup and improved reproducibility.
You provide readers with links to great resources so they can do their own testing and learn more about BBRv2. What do you hope readers will learn?
We hope others will test BBRv2 in high-performance research and education environments. There are still some things that we don’t fully understand, for example there are some cases where CUBIC outperforms BBRv2 on paths with very large buffers. It would be great for this to be better characterized, especially in R&E network environments.
What’s the next step for ESnet research into BBRv2? How will you top things next year?
We want to further explore how well BBRv2 performs at 100G and 400G. We would also like to spend additional time performing a deeper analysis of the current (and newly generated) results to gain insights into how BBRv2 performs compared to other algorithms across varied networking infrastructure. Ideally we would like to provide strongly substantiated recommendations on where it makes sense to deploy BBRv2 in the context of research and educational network applications.
Research and Education Networks (REN) capacity planning and user requirements differ from those faced by commodity internet service providers for home users. One key difference is that scientific workflows can require the REN to move large, unscheduled, high-volume data transfers, or “bursts” of traffic. Experiments may be impossible to duplicate and even one underperforming network link can cause the entire data transfer to fail. Another set of challenges stem from the federated nature of scientific collaboration and networking. Because network performance standards cannot be centrally enforced, performance is obtained as a result of the entire REN community working together to identify best practices and resolve issues. For example:
ESnet has long been focused on developing ways to streamline workflows and reduce network operational burdens on the scientific programs, researchers, and others both those we directly serve and on behalf of the entire R&E network community. Building on the successful Science DMZ design pattern and the Petascale DTN project, the Data Mobility Exhibition (DME) was developed to improve the predictability of data movement between research sites and universities. Many sites use perfSONAR to test end-to-end network performance. The DME allows sites to take this a step farther and test end to end data transfer performance.
DME is a resource that enables the calibration of data transfer performance for a site’s DTNs to ensure that they are performing well by using ESnet’s own test environment, at scale. As part of the DME, system/storage administrators and network engineers have a wide variety of resources available to analyze data transfer performance against ESnet’s standard DTNs, obtain help from ESnet Science Engagement (or from universities, Engagement and Performance Operation Centers) to tune equipment, and to share performance data and network designs with the community to help others. For instance, a 10Gbps DTN should be capable of – at a minimum – transferring one Terabyte per hour. However, we would like to see DTNs > 10G or a cluster of 10G DTNs transfer at PetaScale rates of 6TB/hr or 1PB/week.
Currently, the DME has geographically dispersed benchmarking DTNs in three research locations:
Benchmarking DTNs are also deployed in two commercial cloud environments: Google Drive and Box. All five DME DTN can be used for both upload and download testing allowing users to calibrate and compare their network’s data transfer performance. Additional DTNs are being considered for future capacity. Next generation ESnet6 DTNs will be added in FY22-23, supporting this data transfer testing framework.
DME provides calibrated data sets ranging in size from 100MB to 5TB, so that performance of different sized transfers can be studied.
DOE scientists or infrastructure engineers can use the DME testing framework, built from the Petascale DTN model, with their peers to better understand the performance that institutions are achieving in practice. Here are examples of how past Petascale DTN data mobility efforts have helped large scientific data transfers:
To date, over 100 DTN operators have used DME benchmarking resources to tune their own data transfer performance. In addition, the DME has been added to the NSF-funded Engagement and Performance Operations Center (EPOC) program’s six main scientific networking consulting support services, bringing this capability to a wide set of US Research Universities.
As the ESnet lead for this project, I invite you to contact me for more info (consult@es.net). We also have information up on our knowledge-base website fasterdata.es.net. DME is an easy, effective way to ensure your network, data transfer, and storage resources are operating at peak efficiency!
Operating a highly optimized network across two continents that meets the needs of very demanding scientific endeavors requires a tremendous amount of automation, orchestration, security, and monitoring. Any failure to provide these services can create serious operational challenges.
As we enter the ESnet6 era, ESnet is dedicated to ensuring that we continue to relentlessly push the boundaries of operational excellence and obsessively seek out and improve upon operational risks. Our new High Availability Services Site (HASS) in San Jose, CA. will be a critical component to realizing those goals in our computing platforms and services. ESnet’s HASS will soon provide fully redundant network operations platforms, allowing us to seamlessly maintain services if our operations at LBL are disrupted.
For about a decade, ESnet has augmented its data center operations at Berkeley Lab in California with a small footprint at Brookhaven National Laboratory in New York. This has allowed us to synchronize important information across two sites and to run multiple instances of important services to ensure operational continuity in the case of a failure. While this has provided great stability and reliability, there are limitations. In particular, the 2,500 mile gap across a continent does not let ESnet restore operations without some degree of delay as some key services must be manually transitioned. HASS will enable seamless operational continuity, since the shorter distance between Berkeley and San Jose will let us automatically maintain the active synchronization of operational platforms.
Deployment of HASS involves a team effort of our ESnet Computing Infrastructure, Network Engineering, and Security teams, working together to architect and deploy the next evolution in our computing and service reliability strategy. After finalizing our requirements, we are now working with Equinix, a commercial colocation provider, to deploy a site adjacent to the ESnet6 network. Equinix was able to provide a secure suite in their San Jose facility and this location gives us the capacity, and physical adjacency we require to directly connect this suite to ESnet6 and reach our Berkeley data center comfortably within our demanding latency goals (10ms or less).
As part of standing up HASS , we’ll be installing a new routing platform with a 100G upstream connection to ESnet6 in both San Jose and Berkeley. We’ll also be installing new high performance switching platforms, security services (high throughput firewalls, tapping, black hole routing, etc.), virtualization resources, and several other redundant internal operational platforms. Our existing virtualization platform (ESXi/vSAN) will “stretch” into the new space as part of the same logical cluster we operate in Berkeley. Once this is deployed, even networking services that lack native high availability capabilities will be able to simply “float” between the two physical data centers with data mirrored and striped across both sites.
We’re very excited by the addition of the San Jose HASS, and HASS, in combination with existing reliability resources at Brookhaven, will continue to ensure that ESnet6 has the ability to meet scientific networking community needs for service hosting, disaster recovery, and offsite data replication.
Two graduate students working with ESnet have published their papers recently in IEEE and ACM workshops.


Bibek Shrestha, a graduate student at the University of Nevada, Reno, and his advisor Engin Arslan worked with Richard Cziva from ESnet to publish a work on “INT Based Network-Aware Task Scheduling for Edge Computing”. In the paper, Bibek investigated the use of in-band network telemetry (INT) for real-time in-network task scheduling. Bibek’s experimental analysis using various workload types and network congestion scenarios revealed that enhancing task scheduling of edge computing with high-precision network telemetry can lead up to a 40% reduction in data transfer times and up to 30% reduction in total task execution times by favoring edge servers in uncongested (or mildly congested) sections of the network when scheduling tasks. The paper will appear in the 3rd Workshop on Parallel AI and Systems for the Edge (PAISE) co-conducted with IEEE IPDPS 2021 conference to be held on May 21st, 2021, in Portland, Oregon.
Zhang Liu, a former ESnet intern and a current graduate student at the University of Colorado at Boulder, worked with the ESnet High Touch Team – Chin Guok, Bruce Mah, Yatish Kumar, and Richard Cziva – on fastcapa-ng, ESnet’s telemetry processing software. In the paper “Programmable Per-Packet Network Telemetry: From Wire to Kafka at Scale,” Zhang showed the scaling and performance characteristics of fastcapa-ng, and highlighted the most critical performance considerations that allow the pushing of 10.4 million telemetry packets per second to Kafka with only 5 CPU cores, which is more than enough to handle 170 Gbit/s of original traffic with 1512B MTU. This paper will appear in the 4th International Workshop on Systems and Network Telemetry and Analytics (SNTA 2021) held at the ACM HPCD 2021 conference in Stockholm, Sweden between 21-25 June 2021.
Congratulations Bibek and Zhang!
If you are a networked systems research student looking to collaborate with us on network measurements, please reach out to Richard Cziva. If you are interested in a summer internship with ESnet, please visit this page.
In March 2020, the U.S. Government Office of Management and Budget (OMB) released a draft memo outlining a required migration to IPv6 only. Memorandum M-21-07 was made official on November 19, 2020. Among other things, this memo mandates that 80% of IP-enabled assets on Federal networks are operating in IPv6-only environments by the end of FY 2025.
ESnet is in the process of planning this transition now, to ensure that we provide our users with the support and resources they need to continue their work uninterrupted and unimpeded by the transition. Practically speaking, this means for ESnet that by 2025, all of our nodes will be transitioned to IPv6 address space, and we will not support dual-stacking with IPv4 and IPv6 addresses.
Transitioning to an IPv6-only network has been over a quarter-century in the making for ESnet. Here’s a look back at our history with IPv6
ESnet’s history of helping to develop, support, and operationalize new protocols begins well before the advent of IPv6.
In the early 1990s, Cathy Aronson, an employee of Lawrence Livermore National Laboratory working on ESnet, helped establish a production implementation and support plan for the Open Systems Interconnect (OSI) Connectionless-mode Network Service (CLNS) suite of network protocols. Crucially, Aronson developed a scalable network addressing plan that provided a model for the utilization of the kinds of massive address spaces that OSI CLNS and, later, IPv6 would come to use. CLNS itself was a logical progression from DECnet which had been embraced and supported by ESnet’s precursors (MFEnet and HEPnet).
As the IPv6 draft standard (RFC2460) developed in the 1990s, ESnet staff created an operational support model for the new protocol. The stakes were high; if IPv6 were to succeed in supplanting IPv4, and prevent the ill effects of IPv4 address exhaustion, it would need a smooth roll-out. Bob Fink, Tony Hain, and Becca Nitzan spearheaded early IPv6 adoption processes, and their efforts reached far beyond ESnet and the Department of Energy (DOE). The trio were instrumental in establishing a set of operational practices and testbeds under the auspices of the Internet Engineering Task Force–the body where IPv6 was standardized–and this led to the development of a worldwide collaboration known as the 6bone. 6bone was a set of tunnels that allowed IPv6 “islands” to be connected, forming a global overlay network. More importantly, it was a collaboration that brought together commercial and research networks, vendors, and scientists, all with the goal of creating a robust internet protocol for the future.
Not only were Fink, Hain, and Nitzan critical in this development of what would become a production IPv6 network (their names appear on a number of IETF RFCs), they would also spearhead the adoption of the protocol within ESnet and DOE. In the summer of 1996, ESnet was officially connected to the 6bone; by 1999, the Regional Internet Registries had received their production allocations of IPv6 address space. Just one month later, the first US allocation of that space was made–to ESnet. ESnet has the distinction of being the first IPv6 allocation from ARIN – assigned on August 3, 1999, with the prefix 2001:0400::/32.
Nitzan continued her pioneering work, establishing native IPv6 support on ESnet, and placing what we believe was the first workstation on a production IPv6 network. This was part of becoming the first production network in North America to adopt IPv6 in tandem with IPv4 via the use of an IPv6 “dual-stack.” As US Government requirements and mandates developed in 2005, 2012, and 2014, the ESnet team met these requirements for increased IPv6 adoption, while also providing support and consultation for the DOE community.
Although Aronson, Fink, Hain, and Nitzan have all moved on from ESnet, a new generation of staff continued the spirit of innovation and early adoption. In the early 2010s, ESnet’s internal routing protocols were consolidated around the use of multi-topology Intermediate System to Intermediate System or IS-IS. This allowed for the deployment of flexible and disparate IPv4 and IPv6 topologies, paving the way for the creation of IPv6-only portions of ESnet, allowing the use of optimized routing protocols for the entire network. ESnet’s acquisition strategy has long emphasized IPv6 support and feature parity between IPv4 and IPv6.
As ESnet moves into ESnet6, it is well-positioned to build and expand an IPv6-only network, while retaining legacy support for IPv4 where needed. ESnet will soon finish a two-year project to switch our management plane entirely over to IPv6.
For our customers and those connected to us, here’s what this means:
Zeek is a powerful open source network security monitoring software extensively used by ESnet. Zeek (formally called Bro) was initially developed by researchers at Berkeley Lab; it allows users to identify & manage cyber threats by tracking and logging network traffic activity. Zeek operates as a passive monitor, providing a holistic view of what is transpiring in the network and on all network traffic.
In a previous post, I presented some of our efforts in approaching the WAN security using Zeek for general network monitoring, with successes and challenges found during the process. In this blog post I’ll focus on our efforts in using Zeek as part of security monitoring for the ESnet6 management network – ZoMbis (Zeek on Management based information system).
ZoMbis on the ESnet6 management network:
Most research and educational networks employ a dedicated management network as a best practice. The management network provides a configuration command and control layer, as well as conduits for all of the inter-routing communications between the devices used to move our critical customer data. Because of the sensitive nature of these communications, the management network needs to be protected from external and general user network traffic (websites, file transfers, etc.), and our staff needs to have detailed visibility on management network activity.
At ESnet, we typically use real IP addresses for all internal network resources, and our management network is allocated a fairly large address space block advertised in our global routing table, to help protect against opportunistic hijacking attacks. By isolating our management network from user data streams, the amount of routine background noise is vastly reduced making the use of Zeek, or any network monitoring security capability, much more effective.
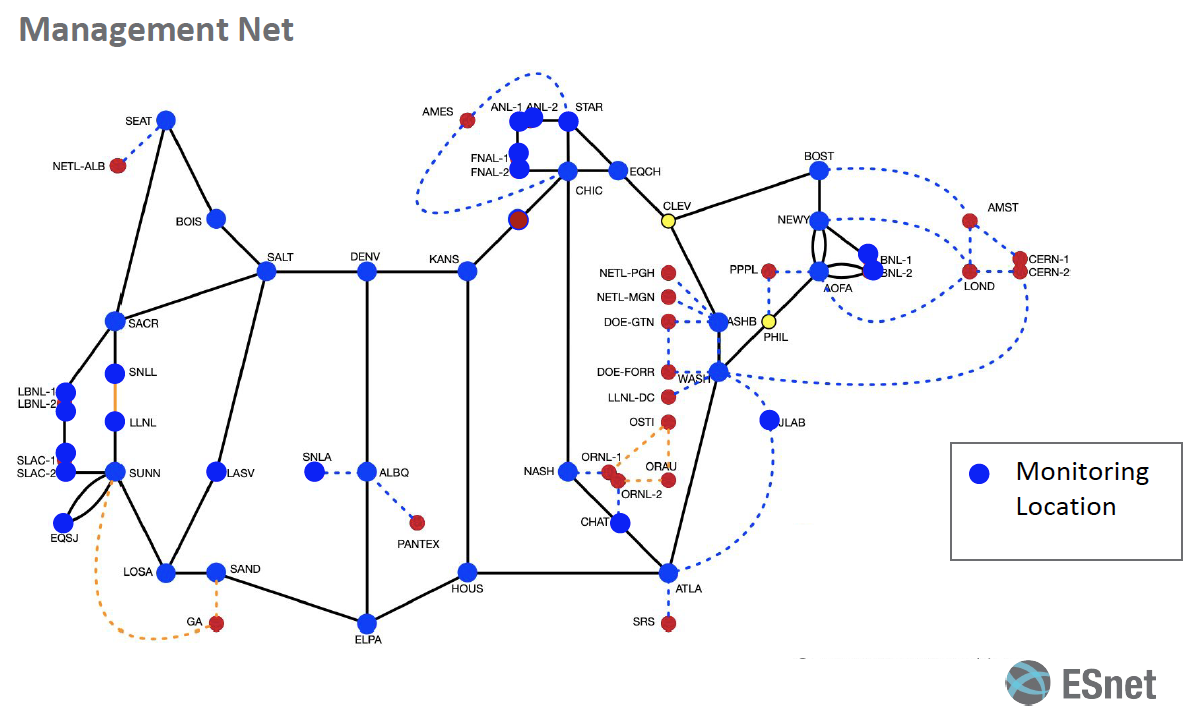
The above diagram shows an overview of the deployment strategy of Zeek on the ESnet6 management network. The blue dots in the diagram show the locations that will have equipment running Zeek instances for monitoring the network traffic on the management network. The traffic from the routers on those locations is mirrored to the Zeek instances using a spanning port, and the Zeek logs generated are then aggregated in our central security information and event logging and management system (SIEM).
Scott Campbell presented ‘Using Zeek in ESnet6 Management Network Security Monitoring’ during virtual Zeek Week held last year that explained the overall strategy for deployment of Zeek on the management network in greater detail. Some ZoMbis deployment highlights are:
ESnet 6’s new management network will use only IPv6. From a monitoring perspective this change from the traditional IPv4 poses a number of interesting challenges; In particular, IPv6 traffic employs more multicast and link-local traffic for local subnet communications. Accordingly, we are in the process of adjusting and adding to Zeek’s policy based detection scripts to support these changes in network patterns. These new enhancements and custom scripts being written by our cybersecurity team to support IPv6 will be of interest to other Zeek users and we will release them to the entire Zeek community soon.
The set of Zeek policy created for this project can be broken out into two general groups. The first of these is protocol mechanics – particularly looking closer between layer 2 and 3 where there are a number of interesting security behaviors with IPv6. A subset of notices that these protocol mechanic policies will provide are:
The second set of Zeek policies that have been developed in support for ZoMbis involves taking advantage of predictable management network behavioral patterns – we build policy to model anticipated behaviors and let us know if something is amiss. For example looking at DNS and NTP behavior we can identify unexpected hosts and data volumes, since we know which systems are supposed to be communicating with one another, and what patterns traffic between these components should follow.
Stay tuned for the part II of this blogpost, where I will discuss ways of using Sinkholing, together with ZoMbis, to provide better understanding and visibility of unwanted traffic upon the management network.
ESnet has recently completed an experiment testing high-performance, file-based data transfers using Data Transfer Nodes (DTNs) on the 100G ESnet Testbed. Within ESnet, new ways to provide optimized, on-demand data movement tools to our network users are being prototyped. One such potential new data movement tool is offered by Zettar, Inc. Zettar’s “zx” product integrates with several storage technologies with an API for automation. This ESnet data movement experiment allowed us to test the use of tools like zx on our network.
Two 100Gbps capable DTNs were deployed on the ESnet Testbed for this work, each with 8 x NVMe SSDs for fast disk-to-disk transfers, and connected using an approximately 90ms round trip time network path. As many readers are aware, this combination of fast storage and fast networking requires careful tuning from both a file I/O and network protocol standpoint to achieve expected end-to-end transfer rates, and this evaluation was no exception. With the help of a storage throughput baseline achieved using the freely available elbencho tool, a single tuning profile for zx was found that struck an impressive performance balance when moving a sweep of hyperscale data sets (>1TB total size or >1M total files or both, see figure below) between the testbed DTNs.
To keep things interesting, the DTN software under evaluation was configured and launched within Docker containers to understand any performance and management impacts, and to establish a potential use case for more broadly deploying DTNs as-a-Service using containerization approaches. Spoiler: the testing was a great success! When configured appropriately, our evaluation has shown that modern container namespaces using performance-oriented Linux networking impart little to no impact on achievable storage and network performance at the 100Gbps scale while enabling a great deal of potential for distributed deployment of DTNs. More critically, the problem of service orchestration and automation becomes the next great challenge when considering any large-scale deployment of dynamic data movement endpoints.
Our takeaways:
For more information, a project report detailing the testing environment, performance comparisons, and best practices may be found here.
You must be logged in to post a comment.