We’re just a few days away from the ESnet6 unveiling and Confab22!
Here’s a great video interview with Ann Almgren, Senior Scientist in CCSE and the Department Head of the Applied Mathematics Department in the Applied Mathematics and Computational Research Division at Berkeley Lab. In it she discusses her research into wind power generation/distribution, and how she will use ESnet6.
Ann Almgren, Berkeley Lab
To watch the unveiling of ESnet6 and learn more about Ann’s research, join us 11 October from 900AM – 12 PM PT at streaming.lbl.gov!
ESnet6 marks a new era of our high-performance network supporting the needs of scientists. We’re able to handle massive flows of data in a reliable, nimble way, and we can specifically configure our setup to match the needs of individual experiments. The upgrade ensures that ESnet is ready to support the future of science today, including the significant increase in the amount of data produced by scientific experiments and the increasingly complex needs of scientists and the way they interact with our network.
Come watch the ESnet6 unveiling ceremony 9AM -12 PM PT, October 11, at streaming.lbl.gov!
As part of a team spanning 15 government, academic, and industrial partners, the Engagement and Performance Operations Center (EPOC) – a collaboration between Indiana University and ESnet – was awarded the “Best HPC Collaboration (Academia/Government/Industry)” HPCwire Readers’ Choice award on Tuesday, Nov. 16. The award, which was made at the High Performance Computing, Networking, Storage and Analysis (SC21) conference, recognizes the effort and collaboration required to move and safeguard irreplaceable data (over 50 years of astronomical observations) from the Arecibo observatory following the structural collapse of this scientific resource in 2016.
At ESnet, Ken Miller, George Robb, and Jason Zurawski supported these efforts as both full members of EPOC and ESnet staff. Both Jason and Ken divide their time between ESnet’s Science Engagement Team, while George is with ESnet’s Infrastructure Systems group. LightBytes looped up with Jason Zurawski to get his thoughts on the project and award, and an update on the Arecibo effort since our post in April 2021 on this project.
Now that data from Arecibo has been migrated to the Texas Advanced Computing Center (TACC), what happens now, and how will this data be used?
The team at the University of Central Florida has been engaged with TACC on several ways to build up the capabilities for their data analysis and sharing requirements. They are working to deploy a portal that will allow researchers access to the data, as well as build workflows to investigate and process using computation provided by TACC.
The team at Arecibo is also still going to process much older data that still resides on tape. Due to the delicate state of the media, it is carefully being read and transferred to on-island storage before being transmitted to TACC for archiving. This work will take several more months to complete.
What do you think the lessons from this effort are in terms of getting so many different organizations to work together to support this very challenging problem?
The collapse that Arecibo experienced sent ripples through the R&E community because researchers and technology professionals alike knew there was a limited window to act on replicating important observations gathered over the years. The partners in this effort were motivated to act, and that removed many barriers to putting some solutions in place. Everyone collaborated efficiently with their core competencies, and we continue to work together as the next steps for the scientific collaboration are planned.
Plans are starting to emerge for a “next generation” Arecibo based on the loss of this instrument, how might the next generation of data management resources be shaped by this collaboration?
Now that there has been some time to evaluate the work, it has also spurred UCF and Arecibo to plan for the future with respect to computation, storage, and network connectivity both in Puerto Rico and in Florida. With these improvements planned, they will be well-positioned to serve the scientific data for years to come. New instruments will no doubt increase the data demands by many orders of magnitude – addressing all aspects of the data pipeline now, and then gradually increasing the capabilities over time, will help to prepare for these emerging challenges.
Congratulations to all of the organizations and staff who helped prevent the loss of this data!
Across the physical sciences, new instruments and capabilities are continuing a relentless growth in data production and need for high speed networking and analysis resources.
ESnet stays on-top of these trends via the Network Requirements Review process, which for the past 15 years has been a remarkable and useful collaboration between the DOE Office of Advanced Supercomputing Research (ASCR), ESnet and science programs across the DOE Office of Science.
The latest Network Requirements Review for the Office of Science High Energy Physics program office (HEP) is now available — among many other findings, this review confirms that the exponential growth of scientific data generation will continue unabated as we proceed into what may well be a new golden age for high energy physics research. Some samples include:
⇾ The upcoming High Luminosity era for the Large Hadron Collider (beyond 2027, or Run-4) will require multi-Tbps network speeds to support globally dispersed “Tier 1” HPC resources. Scientists will use the LHC to uncover how the Higgs-Boson interacts and gives mass to other particles, and explore emerging evidence for particle behaviors not explained by current physics models. Each data-taking year, the experiments, ATLAS and CMS combined, are expected to accumulate roughly 1 EB of new data and it is estimated that complete data set sizes may routinely exceed 100 PB.
Expected maximum luminosity and integrated luminosity for the LHC as a function ofcalendar year, data produced tracks with improved luminosity and resolution
⇾ Scientists at the Deep Underground Neutrino Experiment (DUNE) in South Dakota and at Fermilab in Illinois, will use high speed data transfer to identify supernova events, as part of ongoing measurement of neutrino interactions. Supernovae measured by DUNE will generate over 200TB of compressed data per event, and Research and Educational Networks (REN) must be able to supply highly reliable, predictable data transfer capabilities to provide telescope targeting data to global arrays.
10kt DUNE Far-Detector SP module, showing the alternating 58 m long (into the page), 12 m high anode (A) and cathode (C) planes, as well as the field cage that surrounds the drift regions between the anode and cathode planes. The blank area on the left side was added to show the profile of a single anode plane assembly (APA). Person included for scale.
⇾ The Cosmic Microwave Background, Stage 4 (CMB-S4) experiment will require data management and transfer capabilities in some of the most demanding locations on earth. Operating two observational locations, and multiple telescopes with a combined total of 500,000 cryogenically-cooled superconducting detectors at the South Pole and in the Chilean Atacama Desert, CMB-S4 will provide an unprecedented picture back into the start of the Universe. Operating for seven years in these conditions, 22 TB (~8 TB at the South Pole and ~14 TB in Chile) of data will be generated daily, leading to an accrual of 3 PB annually, and as much as 100 TB over the full program lifecycle.
Two Cross-Dragone (CD) telescopes (one is pictured above) with six meter diameter input apertures will be deployed at the Chilean site to map roughly 70% of the sky every day to support the dark universe, matter-mapping, and time-varying mm-wave sky science goals. Image and caption courtesy of the CMB-S4 Project
Network Requirements Reviews analyze the current, near, and long-term needs of the HEP community, providing a network and data-centric understanding of the scientific process used by the researchers and scientists. These requirements reviews drive ESnet’s investments in new services and capabilities, and enable ESnet to build strong partnerships with Office of Science (SC) programs, PIs, and user facilities. More information on this ESnet requirements review process can be found here.
We would like to thank the 13 HEP projects, and all of the HEP & DOE Office of Science collaborators who generously gave of their time, expertise, and most importantly, their enthusiasm for the future of high energy physics, as part of creating this report.
We want to especially thank the entire Science Engagement team plus Kate Robinson, and Dale Carder with our Network Engineering group who all provided outstanding support and technical expertise.
5.5 Questions with Eli Dart (ESnet), C.S. Chang, and Michael Churchill (PPPL)
In 2025, when the International Thermonuclear Experimental Reactor (ITER) generates “first plasma”, it will be the culmination of almost 40 years of effort. First started in 1985, the project has grown to include the scientific talents of seven members (China, EU, India, Japan, Korea, Russia, and the US, with EU membership bringing the total to 35 countries) and if successful, will mark the first time that a large scale fusion reactor generates more thermal power than is used to heat isotopes of hydrogen gas to a plasma state.
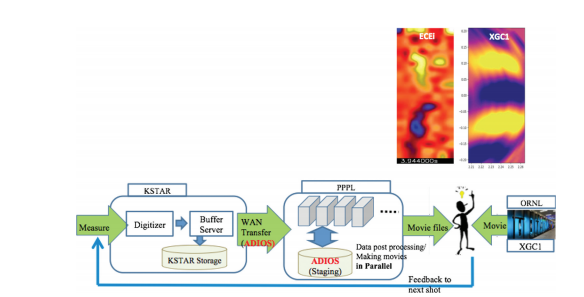
ESnet is supporting this international scientific community as this dream of limitless, clean energy is pursued. When operational at full capacity, ITER will generate approximately a petabyte-per-day of data, much of which will need to be analyzed and fed back in near real-time to optimize the fusion reaction and manage distribution of data to a federated framework of geographically distributed “remote control rooms” or RCR. To prepare for this demanding ability to distribute both data and analytics, recently ESnet’s Eli Dart and the Princeton Plasma Physics Laboratory’s (PPPL) Michael Churchill and C.S. Chang were co-authors on a test exercise performed with collaborators at Pacific Northwest National Laboratory (PNNL), PPPL, Oak Ridge National Laboratory (ORNL), and with the Korean KREONET, KSTAR, National Fusion Research Institute, and the Ulsan National Institute of Science and Technology. This study (https://doi.org/10.1080/15361055.2020.1851073) successfully demonstrated the use of ESnet and the ScienceDMZ architecture as part of trans-Pacific large data transfer, and near real-time movie creation and analysis of the KSTAR electron cyclotron emission images, via links between multiple paths at high sustained speeds.
Q 1: This was a complex test, involving several sites and analytic workflows. Can you walk our readers through the end-to-end workflow?
End-to-end workflow of the demonstration comparing real-time streaming data from the KSTAR ECEI diagnostic to side-by-side movie from XGC1 gyrokinetic turbulence code.
Eli Dart: The data were streamed from a system at KSTAR, encoded into ADIOS format, streamed to PPPL, rendered into movie frames, and visualized at PPPL. One of the key attributes of this workflow is that it is a streaming workflow. Specifically, this means that the data passes through the workflow steps (encoding in ADIOS format, transfer, rendering movie frames, showing the movie) without being written to non-volatile storage. This allows for performance improvements, because no time is spent on storage I/O. It also removes the restriction of storage allocations from the operation of the workflow – only the final data products need to be stored (if desired).
Q 2: A big portion of this research supports the idea of federated, near real-time analysis of data. In order to make these data transfers performant, flexible, and adaptable enough to meet the requirements for a future ITER RCR, you had to carefully engineer and coordinate with many parties. What was the hardest part of this experiment, and what lessons does it offer ITER?
Eli Dart: It is really important to ensure that the network path is clean. By “clean” I mean that the network needs to provide loss-free IP service for the experiment traffic. Because the fusion research community is globally distributed, the data transfers cover long distances, which greatly magnifies the negative impact of packet loss on transfer performance. Test and measurement (using perfSONAR) is very important to ensure that the network is clean, as is operational excellence to ensure that problems are fixed quickly if they arise. KREONET is an example of a well-run production network – their operational excellence contributed significantly to the success of this effort.
Q 3: One of the issues you had to work around was a firewall at one institution. What was involved in working with their site security, and how should those working with Science DMZ work through these issues?
Eli Dart: Building and operating a Science DMZ involves a combination of technical and organizational work. Different institutions have different policies, and the need for different levels of assurance depending on the nature of the work being done on the Science DMZ. The key is to understand that security policy is there for a reason, and to work with the parties involved in the context that makes sense from their perspective. Then, it’s just a matter of working together to find a workable solution that preserves safety from a cybersecurity perspective and also allows the science mission to succeed.
Q 4: How did you build this collaboration and how did you keep everyone on the same page, any advice you can offer other experiments facing the same need to coordinate multi-national efforts?
Eli Dart: From my perspective, this result demonstrates the value of multi-institution, multi-disciplinary collaborations for achieving important scientific outcomes. Modern science is complex, and we are increasingly in a place where only teams can bring all the necessary expertise to bear on a complex problem. The members of this team have worked together in smaller groups on a variety of projects over the years – those relationships were very valuable in achieving this result.
Q 5: In the paper you present a model for a federated remote framework workflow. Looking beyond ITER, are there other applications you can see for the lessons learned from this experiment?
C.S. Chang: Lessons learned from this experiment can be applied to many other distributed scientific, industrial, and commercial applications which require collaborative data analysis and decision making. We do not need to look too far. Expensive scientific studies on exascale computers will most likely be collaborative efforts among geographically distributed scientists who want to analyze the simulation data and share/combine the findings in near-real-time for speedy scientific discovery and for steering of ongoing or next simulations. The lessons learned here can influence the remote collaboration workflow used in high energy physics, climate science, space physics, and others.
Q 5.5: What’s next? You mention quite a number of possible follow on activities in the paper? Which of these most interest you, and what might follow?
Michael Churchill: Continued work by this group has led to the recently developed open-source Python framework, DELTA, for streaming data from experiments to remote compute centers, using ADIOS for streaming over wide-area networks, and on the receiver side using asynchronous Message Passing Interface to do parallel processing of the data streams. We’ve used this for streaming data from KSTAR to the NERSC Cori supercomputer and completing a spectral analysis in parallel in less than 10 minutes, which normally in serial would take 12 hours. Frameworks such as this, enabling connecting experiments to remote high-performance computers, will open up the quality and quantity of analysis workflows that experimental scientists can run. It’s exciting to see how this can help accelerate the progress of science around the world.
Congratulations on your success! This is a significant step forward in building the data management capability that ITER will need.
The simulated storms seen in this visualization are generated from the finite volume version of NCAR’s Community Atmosphere Model. Visualization by Prabhat (Berkeley Lab).
The authors found that there is significant room for improvement in the data transfer capabilities currently in place for CMIP5, both in terms of workflow mechanics and in data transfer performance. In particular, the paper notes that performance improvements of at least an order of magnitude are within technical reach using current best practices.







You must be logged in to post a comment.